출처: 권오흠 교수님


1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
|
package CH1;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Scanner;
public class Code22 {
static String[] words = new String[100000]; // 단어들의 목록
static int[] count = new int[100000]; // 각 단어들의 등장 횟수
static int n = 0; // 목록에 저장된 단어의 개수
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while(true) {
System.out.println("read, find, saveas, exit 중 선택하시오.");
System.out.print("$ ");
String command = sc.next(); // 명령어 입력(4가지 중 하나)
if(command.equals("read")) { // 텍스트 파일을 읽고 인덱스 목록을 만든다.
String filename = sc.next();
makeIndex(filename);
}
else if(command.equals("find")) { // 특정 단어가 몇번 나오는지 횟수를 출력
String str = sc.next();
int index = findWord(str);
if(index != -1) {
System.out.println(words[index] + "(은)는 " + count[index] + "번 나왔습니다.");
}
else {
System.out.println(words[index] + "(은)는 존재하지 않습니다.");
}
}
else if(command.equals("saveas")) { // 인덱스 목록을 파일로 저장
String filename = sc.next();
saveAs(filename);
}
else if(command.equals("exit")) { // 종료
break;
}
}
sc.close();
// 문자열과 나온 횟수 확인
for (int i = 0; i < n; i++) {
System.out.println(words[i] + " " + count[i]);
}
}
// 텍스트 파일을 읽고 인덱스를 만드는 함수
static void makeIndex(String fileName) {
try {
Scanner inFile = new Scanner(new File(fileName)); // 파일로부터 입력 받음
// 파일을 처음부터 끝까지 모두 읽는다(파일에 등장하는 모든 단어들을 확인하기 위해)
while(inFile.hasNext()) {
String str = inFile.next();
addWord(str);
}
inFile.close();
} catch (FileNotFoundException e) { // fileName의 파일이 존재하지 않는 경우
System.out.println("No file");
return;
}
}
// 어떤 문자열이 목록에 이미 있는지 없는지 확인하고 -> 이미 있으면 제외 없으면 추가
static void addWord(String str) {
int index = findWord(str); // returns -1 if not found
if (index != -1) { // found
count[index]++;
}
else { // not found
words[n] = str; // 배열 내 값이 null인 것들(그 전까지는 문자열들로 채워져있고) 중 첫 번째에 문자열을 저장
count[n] = 1; // 새로운 문자열을 추가하면서 동시에 등장 횟수 1로 지정
n++; // 목록에 저장된 단어의 개수 +1
}
}
// words 배열에 어떤 문자열이 존재하지는지, 존재한다면 그 위치(index)를 반환
static int findWord(String str) {
for (int i = 0; i < n; i++) {
if(words[i].equalsIgnoreCase(str)) { // 대소문자 구분하지 않고 동일한지 비교
return i; // 존재한다면 그 위치를 반환
}
}
return -1; // 존재하지 않는다면 -1을 반환
}
// 파일로 저장(출력 = 파일 쓰기)
static void saveAs(String filename){
try {
PrintWriter pw = new PrintWriter(new FileWriter(filename));
for (int i = 0; i < n; i++) {
pw.println(words[i] + " " + count[i]);
}
pw.close();
} catch (IOException e) {
System.out.println("파일 저장 실패");
return;
}
}
}
|
cs |
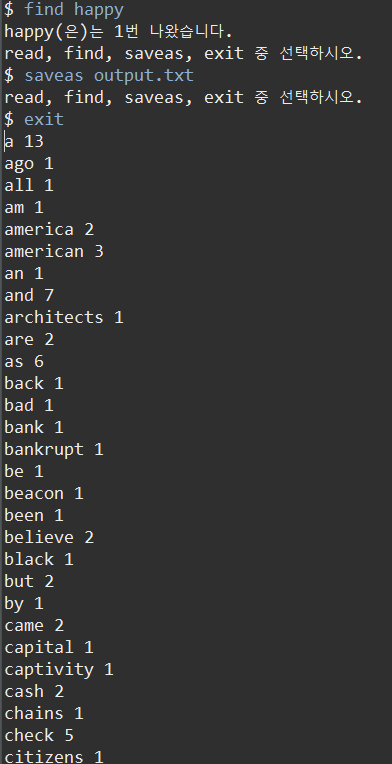
위 코드를 실행시켜 보자.
먼저, 사전에 sample.txt라는 파일을 만들어 두었고, "saveas"를 입력하여 문자열(텍스트)을 파일로 출력(저장)할 때는 output.txt라는 파일을 만들어 저장하도록 한다.
sample.txt 파일의 내용은 다음과 같다.
이제, read, find, saveas, exit를 사용한 결과를 살펴보자.
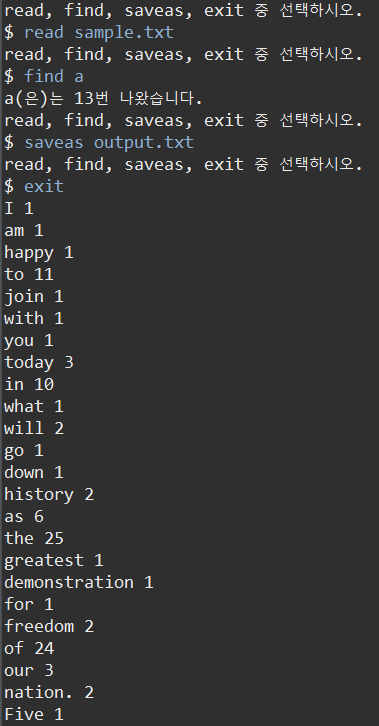
output.txt는
결과를 살펴봤을 때, 발생할 수 있는 문제점들이 있다.
1. 소수점, 쉼표 등의 특수기호가 단어에 포함되는 점
2. 숫자 등이 단어로 취급된다는 점
3. 단어들이 알파벳 순으로 정렬되지 않았다.
이를 해결하는 방법은??
해결방법을 찾기 위해 String 클래스의 기본 메서드들을 살펴보자.
Theme. String 클래스 기본 메서드
1. 문자열 동일성 검사
A라는 문자열이 B라는 문자열과 동일한 문자열인지를 알아보고 싶다?
A.equals(B); 즉, "equals( String )"
equals 메서드는 boolean 값을 반환한다.
만약, 대소문자 구분없이 문자열이 서로 동일한 문자열인지를 알아보고 싶다면?
A.equalsIgnoreCase(B);
간단한 예제를 살펴보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
package CH1;
public class StringClass {
public static void main(String[] args) {
String str1 = "java";
String str2 = "Java";
boolean b1 = str1.equals(str2);
boolean b2 = str1.equalsIgnoreCase(str2);
System.out.println(b1); // false
System.out.println(b2); // true
}
}
|
cs |
2. 문자열 사전식 순서
A라는 문자열과 B라는 문자열 중에 어떤 문자열이 사전식 순서로 더 앞서는지를 알고 싶다면?
A.compareTo(B); 즉, "compareTo( String )"
compareTo 메서드는 int값을 반환한다.
이때, 결과를 잘 해석해야 한다.
만약 A.compareTo(B)의 결과가 0보다 작다면 A가 B보다 사전식 순서가 앞선다는 의미이고, 0보다 크다면 B가 A보다 사전식 순서가 앞선다는 의미이다. 완전히 동일한 문자열일 경우에는 결과가 0이다.
결과는 자릿수의 차이에 따라 다양한 정수로 나오지만 0보다 작냐 크냐로 이해하는 것이 좋다.
왜냐하면 tip이라면 tip일 수있는 것이 A.compareTo(B)의 결과가 0보다 작으면( < 0 ) A < B(A가 앞선다)로 기억하고,
0보다 크면 ( > 0 ) A > B(B가 앞선다)로 기억하면 되기 때문이다.
추가로 compareToIgnoreCase ( String ) 메서드도 존재하는데, 이는 대소문자를 무시하고 사전식 순서를 비교하는 것이다.
예제를 통해 알아보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
package CH1;
public class StringClass {
public static void main(String[] args) {
String str1 = "apple";
String str2 = "banana";
int result1 = str1.compareTo(str2);
System.out.println(result1);// -1
int result2 = str2.compareTo(str1);
System.out.println(result2); // 1
}
}
|
cs |
3. 문자열 길이
어떤 문자열(A)의 길이를 알고 싶다면?
A.length();
( 주의할 것은 배열의 길이를 알고 싶을 때는 array.length로 차이가 있다는 것이다. )
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
package CH1;
public class StringClass {
public static void main(String[] args) {
String str1 = "apple";
String str2 = "banana";
int len1 = str1.length();
int len2 = str2.length();
System.out.println(len1); // 5
System.out.println(len2); // 6
}
}
|
cs |
4. 특정 위치의 문자
ABCDEFG라는 문자열이 있을 때, 3번째 위치에 존재하는 문자 C를 반환하고 싶다면?
charAt( int ) 메서드를 이용한다.
이때, 위치 인덱스는 0부터 시작한다. 따라서, 3번째 위치는 charAt(2)를 통해 값을 반환할 수 있다.
또한, charAt 메서드의 반환값의 자료형은 char type이다.
|
|
package CH1;
public class StringClass {
public static void main(String[] args) {
String str = "ABCDEFG";
char ch = str.charAt(2);
System.out.println(ch); // C
}
}
|
cs |
5. 지정한 문자의 위치 검색
ABCDEFG라는 문자열이 있을 때, C가 존재하는 위치를 알고 싶다면?
indexOf ( char ) 메서드를 이용한다.
이때, 위치 인덱스는 0부터 시작한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
|
package CH1;
public class StringClass {
public static void main(String[] args) {
String str = "ABCDEFG";
int index1 = str.indexOf("C");
int index2 = str.indexOf("F");
System.out.println(index1); // 2
System.out.println(index2); // 5
}
}
|
cs |
6. 지정한 범위의 부분 문자열
ABCDEFG라는 문자열에서 CDE라는 문자열만 떼어내서 반환하고 싶다면?
substring( int, int ) 메서드를 사용한다.
주의할 것이 있다! 해당 메서드를 보다 자세히 살펴보면,
substring( 시작하는 인덱스, 끝나는 인덱스 + 1 ) 이다.
예를 들어, substring( 1, 4 )의 경우에는 인덱스 기준 1부터 3까지의 위치에 존재하는 문자열을 반환하게 된다.
|
|
package CH1;
public class StringClass {
public static void main(String[] args) {
String str1 = "ABCDEFG";
String str2 = str1.substring(2,5);
System.out.println(str2); // CDE
}
}
|
cs |
7. 문자열 자르기
012-3456-789라는 문자열에서 기호가 아닌 문자열만을 잘라내고 싶다면?
구분자(delimiter)를 기준으 split()메서드를 활용한다.
split() 메서드는 그 결과를 String[] 타입의 배열에 각각 저장한다.

만약, "."을 기준으로 split을 하고 싶을 때, split( "." )처럼 작성하면 안된다. 왜냐하면 split 함수에서 구분자를 정규표현식으로 받기 때문이다. 이 경우 split("\\.")으로 작성해주어야 한다.
"."뿐만 아니라 아래의 특수문자들도 \\를 붙여야 한다.

위와 같은 구분자뿐만 아니라 공백을 기준으로도 split을 할 수 있는데,

이제, 위에서 언급한 문제점들을 해결해보자.

trimming이라는 함수를 만들어서, 단어의 앞뒤에 존재하는 특수문자 등을 제거하도록 한다.
이 trimming이라는 함수는 단어를 목록에 저장하기 전에 실행되어야 하므로,
makeIndex 함수 안에서 addWord 함수 이전에 실행되도록 위치시킨다.
trimming 함수에서는 어떤 문자열이 있을 때,
1. 앞에서부터 알파벳이 아닌 문자열들이 존재하는 동안
2. 뒤에서부터 알파벳이 아닌 문자열들이 존재하는 동안
while문을 돌리도록 한다.
이때, 어떤 char이 알파벳인지 아닌지를 판별하기 위해, isLetter( char )라는 메서드를 사용하도록 한다. 반환값의 자료형은 boolean이다.
trimming 함수 부분을 작성한 코드를 살펴보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
static String trimming(String str) {
// i는 문자열의 앞에서부터, j는 뒤에서부터
int i = 0, j = str.length() - 1;
while( i < str.length() && !Character.isLetter(str.charAt(i))) {
i++;
}
while( j >= 0 && !Character.isLetter(str.charAt(j))) {
j--;
}
// 알파벳이 존재하는 문자열의 시작 위치(i), 끝 위치(j)를 얻게됨
if(i > j) // substring에서 오류가 발생하므로
return null;
else
return str.substring(i, j + 1); // substring은 [ )
}
|
cs |
이제, 단어들을 알파벳 순으로 정렬하는 과정을 작성해보자.

이미 정렬되어 있는 목록의 경우 기존에 존재하던 단어가 목록에 추가될 때는 정렬을 해줄 필요가 없다.
따라서, 새로운 문자열이 추가되는 케이스에 대하여 정렬하는 것에 초점을 맞춘다.
정리하자면, 정렬되어 있는 목록에 새로운 단어를 추가하는데, 동시에 정렬이 되도록 하고자 한다.
단어를 추가하기 위해 목록의 뒤에서부터 사전식 순서를 비교하도록 한다. 앞에서부터 비교하면 새로운 단어를 넣기 위해 배열 전체를 한칸씩 뒤로 옮겨야하므로 뒤에서부터 비교하는 것이 더 효율적이기 때문이다.
즉, ordered list에 어떤 값을 insert할 때는 뒤에서부터 비교하면서 insert하는 것이 좋다.
이에 대한 코드는
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// 어떤 문자열이 목록에 이미 있는지 없는지 확인하고 -> 이미 있으면 제외 없으면 추가
static void addWord(String str) {
int index = findWord(str); // returns -1 if not found
if (index != -1) { // found
count[index]++;
}
else { // not found
int i = n-1;
while(i >=0 && words[i].compareTo(str) > 0) {
words[i+1] = words[i];
count[i+1] = count[i];
i--;
}
words[i+1] = str; // 배열 내 값이 null인 것들(그 전까지는 문자열들로 채워져있고) 중 첫 번째에 문자열을 저장
count[i+1] = 1; // 새로운 문자열을 추가하면서 동시에 등장 횟수 1로 지정
n++; // 목록에 저장된 단어의 개수 +1
}
}
|
cs |
이때, "인덱스"를 이해하는 데 부가적인 설명을 덧붙이자면,
위 코드에서 str이 words[5]와 words[6] 사이에 들어가야 정렬이 되는 상황이라고 가정해보자.
순차적으로,
1. i == 6일때, words[6]이 한칸 뒤로 이동
2. i--로 i == 5가 됨
3. i == 5일때, words[5]는 뒤로 이동하지 않음
4. str은 words[6] 자리. 즉, i == 6의 위치에 들어가게 됨. 이때 i == 5이므로 i+1 위치에 str이 들어가는 것
최종적으로 완성된 코드는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
|
package CH1;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Scanner;
public class Code23 {
static String[] words = new String[100000]; // 단어들의 목록
static int[] count = new int[100000]; // 각 단어들의 등장 횟수
static int n = 0; // 목록에 저장된 단어의 개수
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while(true) {
System.out.println("read, find, saveas, exit 중 선택하시오.");
System.out.print("$ ");
String command = sc.next(); // 명령어 입력(4가지 중 하나)
if(command.equals("read")) { // 텍스트 파일을 읽고 인덱스 목록을 만든다.
String filename = sc.next();
makeIndex(filename);
}
else if(command.equals("find")) { // 특정 단어가 몇번 나오는지 횟수를 출력
String str = sc.next();
int index = findWord(str);
if(index != -1) {
System.out.println(words[index] + "(은)는 " + count[index] + "번 나왔습니다.");
}
else {
System.out.println(words[index] + "(은)는 존재하지 않습니다.");
}
}
else if(command.equals("saveas")) { // 인덱스 목록을 파일로 저장
String filename = sc.next();
saveAs(filename);
}
else if(command.equals("exit")) { // 종료
break;
}
}
sc.close();
// 문자열과 나온 횟수 확인
for (int i = 0; i < n; i++) {
System.out.println(words[i] + " " + count[i]);
}
}
// 텍스트 파일을 읽고 인덱스를 만드는 함수
static void makeIndex(String fileName) {
try {
Scanner inFile = new Scanner(new File(fileName)); // 파일로부터 입력 받음
// 파일을 처음부터 끝까지 모두 읽는다(파일에 등장하는 모든 단어들을 확인하기 위해)
while(inFile.hasNext()) {
String str = inFile.next();
String trimmed = trimming(str);
if(trimmed != null) {
String t = trimmed.toLowerCase(); // 소문자로
addWord(t);
}
}
inFile.close();
} catch (FileNotFoundException e) { // fileName의 파일이 존재하지 않는 경우
System.out.println("No file");
return;
}
}
static String trimming(String str) {
// i는 문자열의 앞에서부터, j는 뒤에서부터
int i = 0, j = str.length() - 1;
while( i < str.length() && !Character.isLetter(str.charAt(i))) {
i++;
}
while( j >= 0 && !Character.isLetter(str.charAt(j))) {
j--;
}
// 알파벳이 존재하는 문자열의 시작 위치(i), 끝 위치(j)를 얻게됨
if(i > j) // substring에서 오류가 발생하므로
return null;
else
return str.substring(i, j + 1); // substring은 [ )
}
// 어떤 문자열이 목록에 이미 있는지 없는지 확인하고 -> 이미 있으면 제외 없으면 추가
static void addWord(String str) {
int index = findWord(str); // returns -1 if not found
if (index != -1) { // found
count[index]++;
}
else { // not found
int i = n-1;
while(i >=0 && words[i].compareTo(str) > 0) {
words[i+1] = words[i];
count[i+1] = count[i];
i--;
}
words[i+1] = str; // 배열 내 값이 null인 것들(그 전까지는 문자열들로 채워져있고) 중 첫 번째에 문자열을 저장
count[i+1] = 1; // 새로운 문자열을 추가하면서 동시에 등장 횟수 1로 지정
n++; // 목록에 저장된 단어의 개수 +1
}
}
// words 배열에 어떤 문자열이 존재하지는지, 존재한다면 그 위치(index)를 반환
static int findWord(String str) {
for (int i = 0; i < n; i++) {
if(words[i].equalsIgnoreCase(str)) { // 대소문자 구분하지 않고 동일한지 비교
return i; // 존재한다면 그 위치를 반환
}
}
return -1; // 존재하지 않는다면 -1을 반환
}
// 파일로 저장(출력 = 파일 쓰기)
static void saveAs(String filename){
try {
PrintWriter pw = new PrintWriter(new FileWriter(filename));
for (int i = 0; i < n; i++) {
pw.println(words[i] + " " + count[i]);
}
pw.close();
} catch (IOException e) {
System.out.println("파일 저장 실패");
return;
}
}
}
|
cs |
알파벳(소문자) 단어들만 존재하고, 사전식 순서로 정렬된 모습을 확인할 수 있다.