MySQL - JOIN(1)
여러 개의 표(테이블)로 분산된 정보를 결합해서 하나의 단일한 표로 만드는 기술이 바로 JOIN
관계형 데이터베이스에서 가장 중요한 기능은 JOIN이다.
(학습에 도움이 되는 사이트: https://sql-joins.leopard.in.ua/)

먼저, 아래의 두 가지 경우를 살펴보자.
1. 테이블을 나누기 전(중복된 행을 노란색으로 표시)
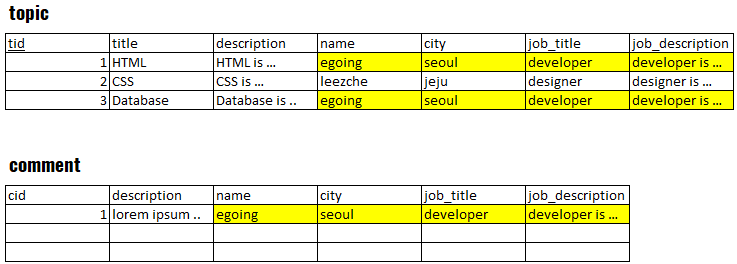
2. 테이블을 나눈 후(중복된 행 제거 목적)

1번의 표들을 2번의 표로 나눈 것이다. 중복을 제거하여 과도하게 데이터 용량을 사용하던 것을 막고, 데이터의 수정이 용이해졌지만, 한편으로는 표를 읽는 것이 불편해졌다.
우리는 데이터를 읽는 목적에 따라 JOIN을 사용할 필요성이 생긴 것이다.
이제, MySQL Workbench에서 2번의 표를 만들고 JOIN에 대해 알아보도록 하자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
use test;
DROP TABLE IF EXISTS `author`;
CREATE TABLE `author` (
`aid` int(11) NOT NULL,
`name` varchar(10) DEFAULT NULL,
`city` varchar(10) DEFAULT NULL,
`profile_id` int(11) DEFAULT NULL,
PRIMARY KEY (`aid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `author` VALUES (1,'egoing','seoul',1),(2,'leezche','jeju',2),(3,'blackdew','namhae',3);
DROP TABLE IF EXISTS `profile`;
CREATE TABLE `profile` (
`pid` int(11) NOT NULL,
`title` varchar(10) DEFAULT NULL,
`description` tinytext,
PRIMARY KEY (`pid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `profile` VALUES (1,'developer','developer is ...'),(2,'designer','designer is ..'),(3,'DBA','DBA is ...');
DROP TABLE IF EXISTS `topic`;
CREATE TABLE `topic` (
`tid` int(11) NOT NULL,
`title` varchar(45) DEFAULT NULL,
`description` tinytext,
`author_id` varchar(45) DEFAULT NULL,
PRIMARY KEY (`tid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `topic` VALUES (1,'HTML','HTML is ...','1'),(2,'CSS','CSS is ...','2'),(3,'JavaScript','JavaScript is ..','1'),(4,'Database','Database is ...',NULL);
|
cs |
Theme. LEFT JOIN

위 그림처럼 LEFT JOIN은 테이블A만 가지고 있는 값(행이라고 생각하는 것이 좋다) + 테이블 A와 B 모두 가지고 있는 값을 나타내게 된다. 이게 도대체 무슨 말인가?
직접 표를 LEFT JOIN해보면서 이해해보자. MySQL에서 미리 준비한 테이블들을 이용하자.
앞으로의 모든 과정에서 topic table을 중심으로 JOIN을 하는 것에 초점을 두도록 하겠다.
select * from topic; 을 해보면,
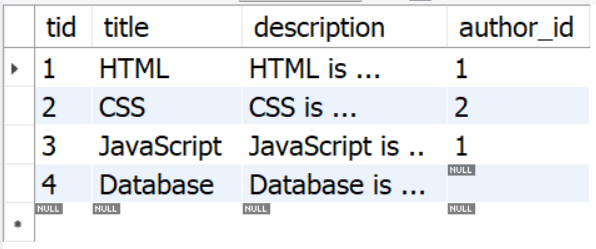
총 4개의 행이 있는데, tid = 4일 때의 author_id 값이 NULL임을 알 수 있다.
select * from author;을 해보면,
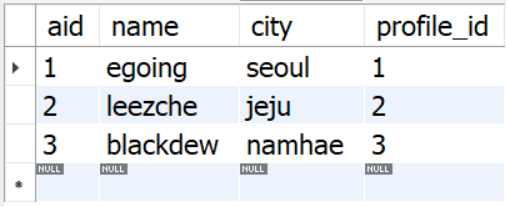
총 3개의 행이 있고, NULL값이 없다.
이제, topic 테이블과 author테이블을 LEFT JOIN해보려 하는데, JOIN을 할 때 topic 테이블의 author_id와 author 테이블의 aid가 같은 값을 가지는 것을 참고한다.
select * from topic left join author on topic.author_id = author_aid;
(위에 코드는 select * from topic t left join author a on t.author_id = a.aid; 라고 작성할 수 있다.)

테이블의 왼쪽에는 topic 테이블이, 오른쪽에는 author 테이블이 JOIN되었고,
topic 테이블에는 존재하는 행이 author 테이블에는 존재하지 않지만, JOIN 결과 author 테이블 영역 밑에 NULL 값으로 채워진 행이 생성된 것을 확인할 수 있다.
즉, 왼쪽에 있는 테이블에는 값이 있는데, 그 값에 해당하는 오른쪽 테이블에는 행이 없다면, 왼쪽의 테이블의 행을 기준으로 출력되기 전에 NULL이 생긴다.
이 결과에 profile 테이블을 추가적으로 LEFT JOIN 해보자.
select * from profile;

profile 테이블은 3개의 행이 존재한다.
author 테이블의 profile_id 값과 profile 테이블의 pid 값을 참고하여 JOIN해보면,
select * from topic left join author on topic.author_id = author.aid left join profile on author.profile_id = profile.pid;
( select * from topic t left join author a on t.author_id = a.aid left join profile p on a.profile_id = p.pid;)

profile 테이블 또한 author 테이블과 같이 행이 3개이기 때문에 JOIN 결과 NULL 값으로 구성된 행이 추가됨을 알 수 있다.
이제 필요한 컬럼명들만 선택하여 출력해보자.
|
1
2
3
4
5
6
7
8
|
SELECT tid, t.title, author_id, name, p.title AS job_title
FROM topic t LEFT JOIN author a ON t.author_id = a.aid
LEFT JOIN profile p ON a.profile_id = p.pid;
/*
t.title, p.title로 구분해주는 이유는 title이라는 컬럼명이 topic 테이블에도
profile 테이블에도 존재하기 때문에 어떤 테이블의 컬럼명인지를 구분하기 위함이다.
*/
|
cs |
결과는,

위의 코드에 WHERE을 통해 조건(aid = 1이도록)도 추가해보면,
|
1
2
3
4
5
6
|
SELECT tid, t.title, author_id, name, p.title AS job_title
FROM topic t LEFT JOIN author a ON t.author_id = a.aid
LEFT JOIN profile p ON a.profile_id = p.pid
where aid = 1;
|
cs |
결과는,
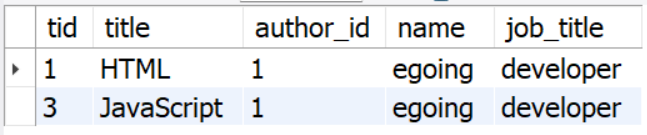
Theme. INNER JOIN
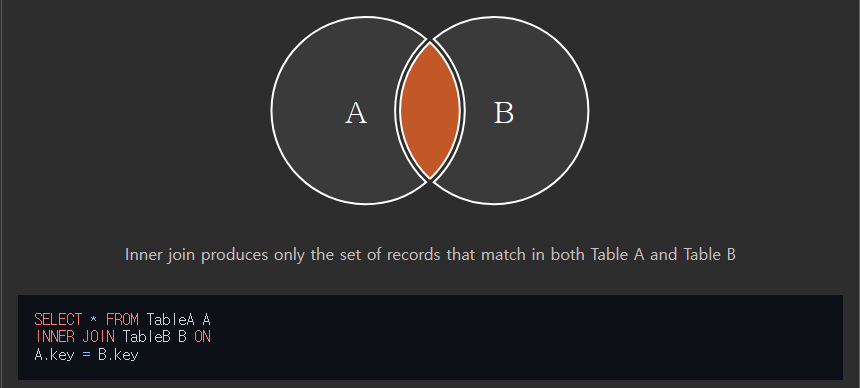
위 그림을 보면, 교집합이 떠오를 것이다.
즉, 테이블 A와 B가 모두 가지고 있는 값(행)만 가지고 새로운 표를 만드는 것이다. 따라서, NULL행은 존재할 수 없다.
INNER를 생략하고 JOIN이라고만 코드를 작성해도 INNER JOIN으로 인식한다.
위의 테이블 결과들을 이용해서 topic 테이블과 author 테이블을 INNER JOIN 해보자.
topic 테이블은 4행, author 테이블은 3행을 가지고 있으므로 JOIN 결과 3행의 값들만 나타날 것이다.
select * from topic t inner join author a on t.author_id = a.aid;

여기에 profile 테이블도 INNER JOIN해보면,
select * from topic t inner join author a on t.author_id = a.aid inner join profile p on a.profile_id = p.pid;

마찬가지로 3행의 결과만 출력되는 것을 확인할 수 있다. (profile 테이블도 3행이다)
Theme. FULL OUTER JOIN
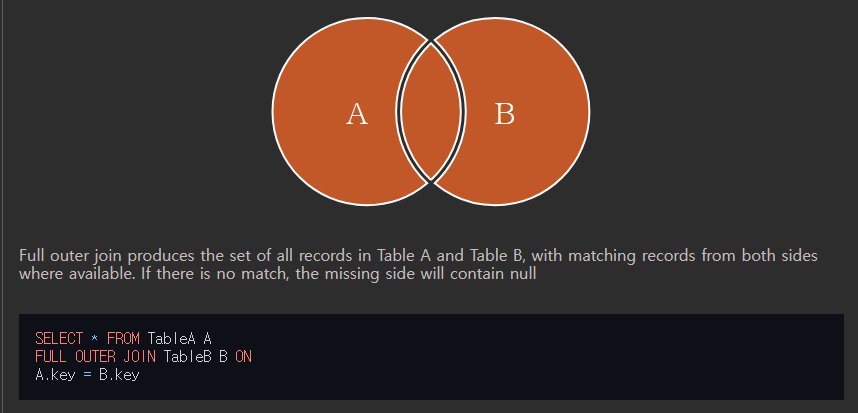
위 그림을 보면, 합집합이 떠오를 것이다.
즉, 테이블 A와 B가 가지고 있는 값(행) 모두를 가지고 새로운 표를 만드는 것이다.
그런데, MySQL에서는 FULL OUTER JOIN을 통해 JOIN할 수 없다.
이때 사용하는 것이 "union"이다. 앞서 설명은 하지 않았지만, RIGHT JOIN은 LEFT JOIN의 반대로 생각해주면 된다.
어떻게 union을 사용하는지 살펴보자.
topic 테이블과 author 테이블을 FULL OUTER JOIN한다면,
|
1
2
3
4
5
|
select *
from topic t left join author a on t.author_id = a.aid
union
select *
from topic t right join author a on t.author_id = a.aid;
|
cs |

결과를 해석해보자.
먼저, topic 테이블과 author 테이블은 3행에 대한 값을 모두 가진다. 그래서 위 3개의 행이 나타났고,
4번째 행은 topci 테이블에만 존재하는 행이므로 author 테이블의 영역에서는 NULL값이 나타났다.
마지막으로, author 테이블에는 존재하지만, topic 테이블에 존재하지 않는 행이 맨 마지막에 나타났다.
Theme. SELF JOIN
한 마디로 테이블 자기 자신을 자신에 조인하는 것(?)이라고 말할 수 있을 것이다.
이는 예제로 이해하는 것이 가장 이해하기 좋다.
위와는 다른 테이블을 이용해보도록 한다.
employees 라는 테이블이 있다고 가정해보자. 그 테이블의 데이터의 일부는 아래와 같다.

컬럼명 중에서 employee_id와 manager_id를 찾아보자.
간단하게 설명하면, employee_id는 직원, manager_id는 각 직원에 대한 사수이다.
그런데, manager_id는 결국 직원 중 한명이므로 employee_id를 가진다.
이때, 각 직원에 대해 사수는 누구인지를 알고 싶다고 가정해보자. 이를 알아보기 위해서는
직원의 manager_id가 결국 사수의 employee_id와 같다는 것을 이용해야 한다.
즉,
|
1
2
3
|
select emp.first_name, emp.manager_id, mgr.employee_id, mgr.first_name
from employees emp join employees mgr -- emp:직원 mgr:사수
on emp.manager_id = mgr.employee_id;
|
cs |
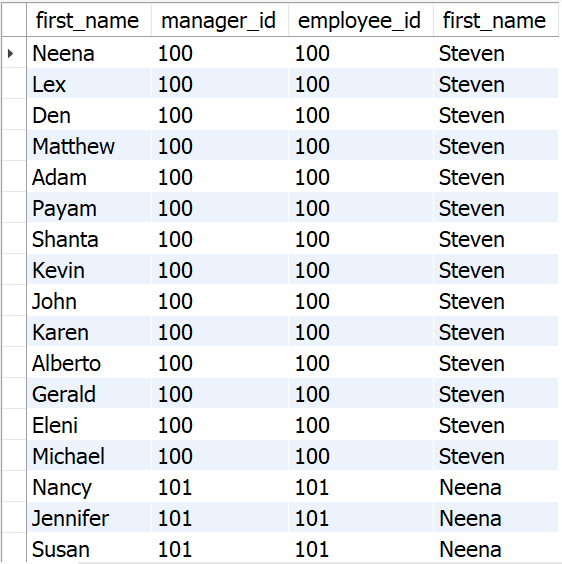
첫 번째 column은 직원을, 4번째 column은 직원에 대한 사수를 의미한다.
이외에도 다양한 종류의 JOIN이 있으나, 정리할 필요가 있을 시 내용을 추가하도록 한다. 끝.